Langchain + Supabase Vector Filtering for RAG Applications

Supabase, acclaimed as an open-source alternative to Firebase, offers a comprehensive toolkit including database, authentication, and storage solutions. Excelling in crafting Minimum Viable Products (MVPs) and hackathon creations, it's particularly adept for building RAG (Retrieval-Augmented Generation) applications. In this guide, I'll demonstrate how to leverage Supabase to enhance your RAG application's efficiency.
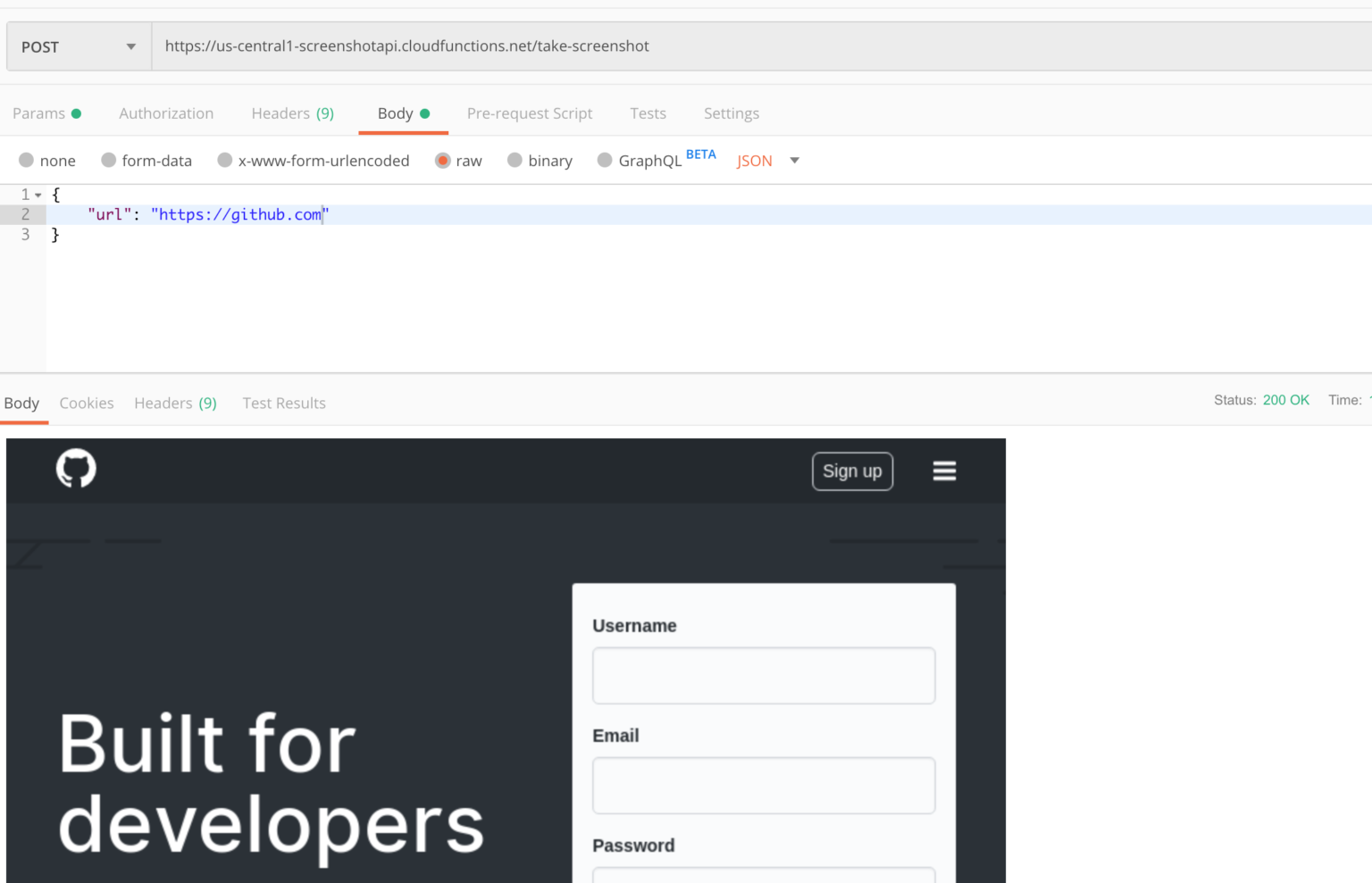
Here's the workflow: Whenever a user uploads a document, we store its vector representation in Supabase. This vector acts as a unique fingerprint of the document's content. Later, when a query is raised, Supabase springs into action, searching for vectors that closely match the query. This search process efficiently retrieves the most relevant documents.